Foro Formación Hadoop
Optimización Aplicaciones Kafka - Spark Streaming
Optimización Aplicaciones Kafka - Spark Streaming
Una vez tenemos diseñada/implementada nuestra aplicación de Kafka – Spark Streaming nos podemos encontrar con la problemática de que no funciona tal y como esperábamos.
A continuación os indico una breve descripción de los pasos/recomendaciones principales a seguir para realizar/optimizar nuestra aplicación de Spark Streaming:
Paso 1: Utilizar el API DirectStream
Para conectar con Kafka disponemos de 2 opciones:
- Conexión a través de un Reciver: Este API te proporciona un único RECEIVER que obtiene los mensajes de Kafka y actualiza el offset (Zookeeper u otro sistema distribuido) una vez se han consumido los mensajes por la aplicación de Spark Streaming. A su vez, Spark Streaming también realiza un checkpoint en el HDFS para en caso de caída de la aplicación de Spark Streaming poder volver a levantar la aplicación y continuar por el estado en el que se quedó.
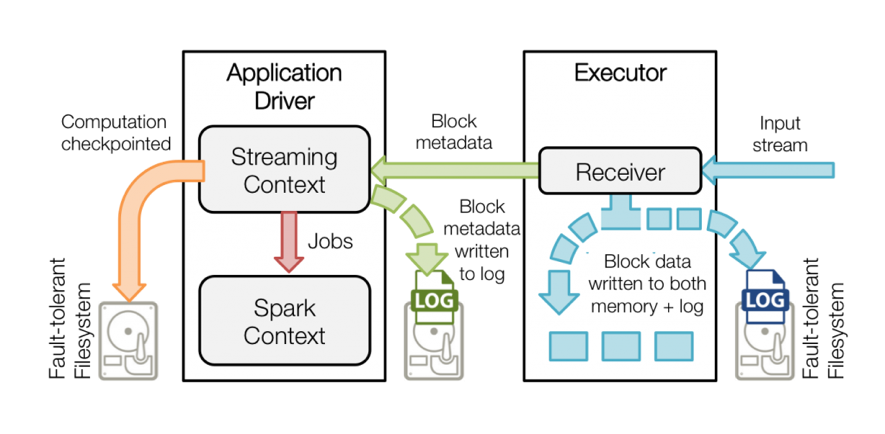
- El proceso anterior podría provocar una “inconsistencia del sistema”, ya que se están almacenando de manera independiente el offset de consumo del mensaje en Kafka y por otra parte el estado del procesamiento en Spark Streaming.
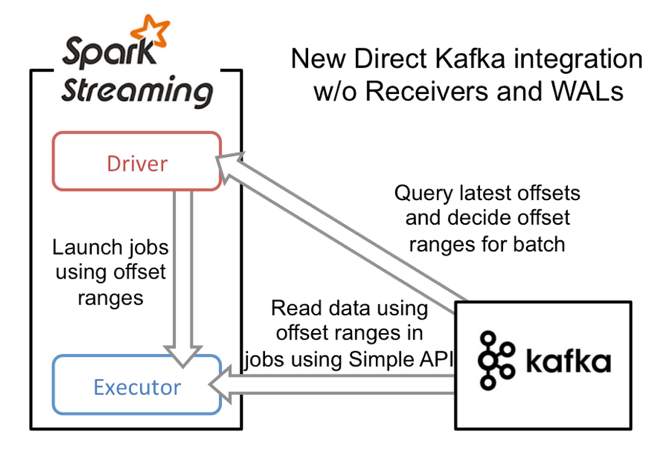
DirectStream: Se recomienda para garantizar la consistencia, “exactly-once” y la paralelización del procesamiento.
- A través del DirectStream lo que se obtiene es un único punto de almacenamiento del “offset” a través de la aplicación de Spark Streaming en la creación del checkpointing.
- DirectStream realiza la paralelización automáticamente. Genera tantas particiones de RDDs como particiones tenga Kafka.
Paso 2: Serializar con Kryo
- Por defecto Spark serializa los objetos con “java serialization”. Se recomienda utilizar Kryo.
- Utilizar Kryo nos va a proporcionar mejor rendimiento y ahorro de memoria en nuestro sistema.
Paso 3: Monitorizar la aplicación para realizar el “tuning” de la memoria.
Sobre todo hay que prestarle atención al Garbage Collector.
- Garbage Collector
- Normalmente en Java se utilizan una de estas dos estrategias: Concurrent Mark Sweep (CMS) gargabe collection y ParallelOld garbage collection.
- A partir de Java 1.6 se obtiene Garbage-First GC (G1 GC): Alto rendimiento y baja latencia.
- Para realizar un “tuning” del Garbage collector es necesario realizar un estudio del funcionamiento de la aplicación.
- Propiedades principales a revisar de Spark:
|
spark.executor.memory |
Cantidad de memoria utilizada por cada “executor”. |
|
spark.executor.cores |
Número de cores utilizado por cada “executor” |
|
spark.dynamicAllocation.enabled |
Esta propiedad se utiliza para que Spark libere al “pool” de YARN los recursos que no esté utilizando en ese momento, cuando vuelva a necesitarlos los solicitará nuevamente a YARN. |
|
spark.shuffle.consolidateFiles |
Si se activa (true), reduce el número de archivos intermedios para la fase del “shuffle”. Mejora el rendimiento en aplicaciones con muchas fases reducer, y en sistemas de ficheros ext4 o xfs. En ext3 puede decrementar el rendimiento en clusters de más de 8 nodos. |
|
spark.storage.memoryFraction |
Propiedad deprecada a partir de la 1.6 de Spark. De la memoria que se le asigna a los “executors” el 60% está reservado para cachear y el resto para la ejecución (0.4). A partir de la 1.6 esto es dinámico. |
|
spark.streaming.backpressure.enabled |
Recomendable cuando tenemos situaciones de que el procesamiento del batch dura más que el intervalo del batch. Se encarga de controlar que eso no suceda dependiendo de lo que ha tardado el procesamiento anterior. |
|
spark.streaming.kafka.maxRatePerPartition
|
Si se desea limitar el número de eventos que obtiene el DirectStream por partición (ligada a la propiedad anterior) |
Kafka
Particionado y replicación
- Una buena práctica a la hora de generar un topic en Kafka es asignar al menos una partición por disco físico de almacenamiento.
- Para evitar la pérdida de mensajes, también es recomendable asignar una réplica por cada partición (como mínimo).
- Ante la caída de un broker y tras la recuperación del mismo, deberíamos reasignar nuevamente las particiones para evitar tener un broker sin carga de trabajo.
- A través del Cloudera Manager podemos indicarle que el balanceo lo realice automáticamente seteando la siguiente propiedad:
auto.leader.rebalance.enable = true
Límite de ficheros abiertos
- Kafka necesita abrir múltiples ficheros (dependiendo del número de topics-particiones-réplicas que estén configuradas en cluster). Por defecto el límite de ficheros abiertos de unix es de 1024 por lo que esto puede provocar un problema. Para evitar esto se recomienda Cloudera recomienda subir ese valor a 32768 (/etc/security/limits.conf)
- num.io.threads: Para lograr un mejor rendimiento se recomienda empezar con el mismo número de discos dedicados a Kafka.
- Garbage Collector: Igual que sucede con Spark, el GC puede provocar un deterioro del rendimiento de Kafka. Si se detecta esto se recomienda utilizar el nuevo GC “G1 garbage-first collector” (kafka-env.sh).
Fuentes:
- https://databricks.com/blog/2015/03/30/improvements-to-kafka-integration-of-spark-streaming.html
- https://spark.apache.org/docs/latest/streaming-kafka-integration.html
- http://blog.cloudera.com/blog/2015/03/exactly-once-spark-streaming-from-apache-kafka/
- http://fdahms.com/2015/10/04/writing-efficient-spark-jobs/
- http://lordjoesoftware.blogspot.com.es/2015/02/using-kryoserializer-in-spark.html
- https://databricks.com/blog/2015/05/28/tuning-java-garbage-collection-for-spark-applications.html
- http://www.slideshare.net/SparkSummit/kaczmarek-yi
- https://groups.google.com/forum/ - !topic/kryo-users/depYM888V_A
- https://www.cloudera.com/documentation/kafka/latest/topics/kafka_performance.html#concept_exp_hzk_br
- http://www.confluent.io/blog/how-to-choose-the-number-of-topicspartitions-in-a-kafka-cluster/
- https://community.hortonworks.com/articles/49789/kafka-best-practices.html
- http://www.slideshare.net/miguno/apache-kafka-08-basic-training-verisign
- https://www.linkedin.com/pulse/how-choose-number-topicspartitions-kafka-cluster-gaurhari-dass
Firmado: Fernando Agudo
Redes sociales