Foro Formación Hadoop
Ejecución WorkFlow de Oozie con acciones de Pig, Hive y Sqoop
Ejecución WorkFlow de Oozie con acciones de Pig, Hive y Sqoop
Executing an Oozie workflow with Pig, Hive & Sqoop actions

Before running a Hive query, the table/column/column-types have to be defined. Because of this, the data for Hive needs to have some structure. Pig is better for processing semi structured data when compared to Hive. Here is Pig vs Hive at a very high level. Because of the above mentioned reason, one of the use case is that Pig being used for pre-processing (filter out the invalid records, massage the data etc) of the data to make it ready for Hive to consume.
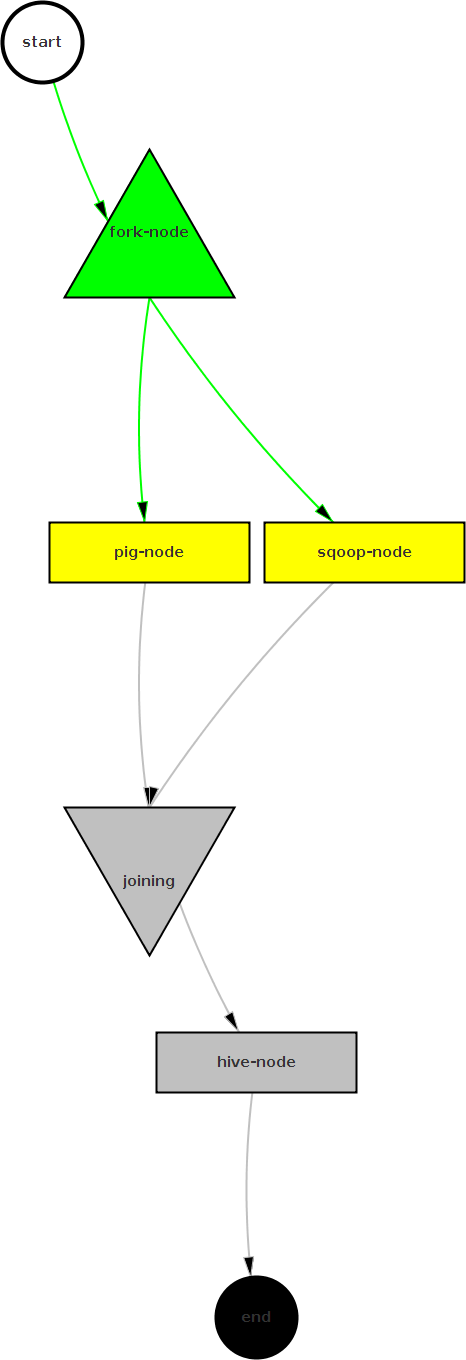
The below DAG was generated by Oozie. The fork will spawn a Pig action (which cleans the Click Stream data) and a Sqoop action (which imports the user data from a MySQL database) in parallel. Once the Pig and the Sqoop actions are done, the Hive action will be started to do the final analytics combining the Click Stream and the User data.
- The work flow requires more than 2 map slots in the cluster, so if the work flow is executed on a single node cluster the following has to be included in the `mapred-site.xml`.
|
1
2
3
4
5
6
7
8
|
<property> <name>mapred.tasktracker.map.tasks.maximum</name> <value>4</value></property><property> <name>mapred.tasktracker.reduce.tasks.maximum</name> <value>4</value></property> |
|
1
2
3
4
5
6
7
8
9
10
11
|
1,www.bbc.com1,www.abc.com1,www.gmail.com2,www.cnn.com2,www.eenadu.net2,www.stackoverflow.com2,www.businessweek.com3,www.eenadu.net3,www.stackoverflow.com3,www.businessweek.comA,www.thecloudavenue.com |
|
1
2
3
4
5
6
7
|
CREATE TABLE user ( user_id INTEGER NOT NULL PRIMARY KEY, name CHAR(32) NOT NULL, age INTEGER, country VARCHAR(32), gender CHAR(1)); |
|
1
2
3
|
insert into user values (1,"Tom",20,"India","M");insert into user values (2,"Rick",5,"India","M");insert into user values (3,"Rachel",15,"India","F"); |
- Copy the above mentioned `share` folder into HDFS. Here is the significance of sharelib in Oozie. These are the common libraries which are used across different actions in Oozie.
|
1
|
bin/hadoop fs -put /home/vm4learning/Code/share/ /user/vm4learning/share/ |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
|
<?xml version="1.0" encoding="UTF-8"?><workflow-app xmlns="uri:oozie:workflow:0.2" name="cs-wf-fork-join"> <start to="fork-node"/> <fork name="fork-node"> <path start="sqoop-node" /> <path start="pig-node" /> </fork> <action name="sqoop-node"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <prepare> <delete path="${nameNode}/${examplesRootDir}/input-data/user"/> </prepare> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <command>import --connect jdbc:mysql://localhost/clickstream --table user --target-dir ${examplesRootDir}/input-data/user -m 1</command> </sqoop> <ok to="joining"/> <error to="fail"/> </action> <action name="pig-node"> <pig> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <prepare> <delete path="${nameNode}${examplesRootDir}/intermediate"/> </prepare> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <script>filter.pig</script> <param>INPUT=${examplesRootDir}/input-data/clickstream</param> <param>OUTPUT=${examplesRootDir}/intermediate</param> </pig> <ok to="joining"/> <error to="fail"/> </action> <join name="joining" to="hive-node"/> <action name="hive-node"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <prepare> <delete path="${nameNode}/${examplesRootDir}/finaloutput"/> </prepare> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>script.sql</script> <param>CLICKSTREAM=${examplesRootDir}/intermediate/</param> <param>USER=${examplesRootDir}/input-data/user/</param> <param>OUTPUT=${examplesRootDir}/finaloutput</param> </hive> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Sqoop failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message> </kill> <end name="end"/></workflow-app> |
|
1
2
3
4
5
6
7
8
9
|
nameNode=hdfs://localhost:9000jobTracker=localhost:9001queueName=defaultexamplesRoot=oozie-clickstream-examplesexamplesRootDir=/user/${user.name}/${examplesRoot}oozie.use.system.libpath=trueoozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/apps/cs |
|
1
2
3
4
5
6
7
|
DROP TABLE clickstream;CREATE EXTERNAL TABLE clickstream (userid INT, url STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION '${CLICKSTREAM}';DROP TABLE user;CREATE EXTERNAL TABLE user (user_id INT, name STRING, age INT, country STRING, gender STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LOCATION '${USER}';INSERT OVERWRITE DIRECTORY '${OUTPUT}' SELECT url,count(url) c FROM user u JOIN clickstream c ON (u.user_id=c.userid) where u.age<16 group by url order by c DESC LIMIT 3; |
|
1
2
3
|
clickstream = load '$INPUT' using PigStorage(',') as (userid:int, url:chararray);SPLIT clickstream INTO good_records IF userid is not null, bad_records IF userid is null;STORE good_records into '$OUTPUT'; |
|
1
|
bin/oozie job -oozie http://localhost:11000/oozie -config /home/vm4learning/Code/oozie-clickstream-examples/apps/cs/job.properties -run |

- The output should appear as below in the `oozie-clickstream-examples/finaloutput/000000_0` file in HDFS.
|
1
2
3
|
www.businessweek.com 2www.eenadu.net 2www.stackoverflow.com 2 |
- It's better to test the individual actions like Hive, Pig and Sqoop independent of Ooize and later integrate them in the Oozie work flow.
- The Oozie error messages very cryptic and the MapReduce log files need to be looked to figure out the actual error.
- The Web UI which comes with Oozie is very rudimentary and clumsy, need to look into some of the alternatives.
- The XML for creating the work flows is very verbose and is very error prone. Any UI for creating workflows for Oozie would be very helpful.
Will look into the alternatives for some of the above problems mentioned in a future blog entry.
Fuente: http://www.thecloudavenue.com/2013/10/executing-oozie-workflow-with-pig-hive.html
Social networks