Foro Formación Hadoop
Error al generar archivo Wordcount-1.jar
Buenas noches, ya generé el archivo wordcount-1.jar, pero al momento de ejecutarlo me sale el siguiente error adjunto en la imágen.

A que se puede deber?
Gracias.
Hola Rubén,
Necesitaríamos ver los logs propios de las tareas. Dentro de la web del ResourceManager puedes acceder a los logs. Revisa la implementación (tanto el código como los imports, y vuelve a generar el .jar).
Si no te funciona envíanos el código que estás ejecutando para que podamos ayudarte.
Un saludo,
Gracias, ya pude resolver el problema, era por un permiso en la carpeta /user/history del Hdfs.
Ahora sale el siguiente error: The auxService:mapreduce_suffle does not exist.
Investigando en internet sugieren modificar el archivo yarn-site.xml, pero éste se encuentra en varios directorios, alguna otra sugerencia?.
Saludos.
Hola Fernando/alumnos del aula, para ejecutar el wordcount-1.jar realizo los siguientes pasos:
Levantar Servicios:
---------------------
cd /etc/init.d
sudo ./hadoop-hdfs-namenode start
sudo ./hadoop-hdfs-datanode start
sudo ./hadoop-hdfs-journalnode start
sudo ./hadoop-hdfs-secondarynamenode start
sudo ./hadoop-yarn-nodemanager start
sudo ./hadoop-yarn-resourcemanager start
Quitar el modo seguro al Hdfs
-----------------------------
sudo -u hdfs hadoop dfsadmin -safemode leave
Importar archivo Jar al Hdfs
----------------------------
cd Desktop
hadoop fs -put wordcount-1.jar /tmp
Ejecutar Jar:
-------------
hadoop jar wordcount-1.jar wordcount.WordCountDriver /user/cloudera/cervantes/novela /user/cloudera/salida10
Y me sigue saliendo el mismo error:
The auxService:mapreduce_suffle does not exist.
Investigando en internet sugieren modificar el archivo /etc/haddop/conf/yarn-site.xml, y que agregue lo siguiente:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
Pero cuando agrego lo indicado en el archivo /etc/haddop/conf/yarn-site.xml, ahora sale el siguiente error:
20/08/07 09:50:57 INFO mapreduce.Job: Task Id : attempt_1596818118337_0001_m_000001_1, Status : FAILED
Error: org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block: BP-333635372-127.0.0.1-1508779710286:blk_1073742863_2041 file=/user/cloudera/cervantes/teatro/Los banos de Argel_cervantes.txt
at org.apache.hadoop.hdfs.DFSInputStream.refetchLocations(DFSInputStream.java:1040)
at org.apache.hadoop.hdfs.DFSInputStream.chooseDataNode(DFSInputStream.java:1023)
at org.apache.hadoop.hdfs.DFSInputStream.chooseDataNode(DFSInputStream.java:1002)
at org.apache.hadoop.hdfs.DFSInputStream.blockSeekTo(DFSInputStream.java:642)
at org.apache.hadoop.hdfs.DFSInputStream.readWithStrategy(DFSInputStream.java:895)
at org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:954)
at java.io.DataInputStream.read(DataInputStream.java:149)
at org.apache.hadoop.mapreduce.lib.input.UncompressedSplitLineReader.fillBuffer(UncompressedSplitLineReader.java:62)
at org.apache.hadoop.util.LineReader.readDefaultLine(LineReader.java:216)
at org.apache.hadoop.util.LineReader.readLine(LineReader.java:174)
at org.apache.hadoop.mapreduce.lib.input.UncompressedSplitLineReader.readLine(UncompressedSplitLineReader.java:94)
at org.apache.hadoop.mapreduce.lib.input.LineRecordReader.skipUtfByteOrderMark(LineRecordReader.java:144)
at org.apache.hadoop.mapreduce.lib.input.LineRecordReader.nextKeyValue(LineRecordReader.java:184)
at org.apache.hadoop.mapred.MapTask$NewTrackingRecordReader.nextKeyValue(MapTask.java:562)
at org.apache.hadoop.mapreduce.task.MapContextImpl.nextKeyValue(MapContextImpl.java:80)
at org.apache.hadoop.mapreduce.lib.map.WrappedMapper$Context.nextKeyValue(WrappedMapper.java:91)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:144)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:793)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1917)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
Alguna otra sugerencia?.
Saludos.Tambien tengo problemas para ejecutar el wordcount-1.jar, la verdad que no soy experto java y no pude encontrar la causa de este error. Ver imagen adjunta
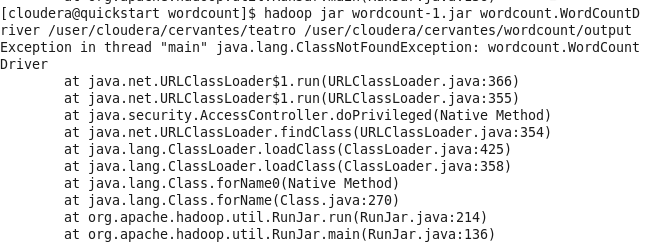
Hola Diego, aparentemente el archivo Jar que estas usando no referencia a las librerias/clases o rutas correctas. Te comparto mi archivo Jar:
https://formacionhadoop.com/aulavirtual/pluginfile.php/46/mod_forum/post/633/wordcount-1.jar
Saludos.
Redes sociales