Proporcionan una estructura de datos persistente para pares key/value de forma binaria.
En el mismo fichero se almacenan los metadatos que contienen la información de ese fichero (tipo de los datos, nombre, fecha,...).
Este tipo de ficheros se usa muy a menudo en Jobs MapReduce, sobre todo cuando la salida de un Job es la entrada de otro.
También, podemos imaginarlos como ficheros de log donde cada registro es una nueva línea.
Son un tipo de fichero muy adecuados para MapReduce porque además son splittable (que se pueden fragmentar).
Pueden almacenar distintos tipos de datos gracias a que usan una gran variedad de frameworks de serialización.
Soportan compresión, que puede ser de 3 tipos:
- Uncompressed (No comprimido)
- Record Compressed (Compresión a nivel de cada par key/value)
- Block Compressed (Se comprime por bloques)
Sea cual sea el tipo de compresión que utilice, la estructura del encabezado (header) va a ser el mismo, sólo que éste contendrá la información necesaria para su posterior lectura.
Problemas:
Problemas:
- Sólo se puede acceder a ellos a través de la AP Java de Hadoop.
- Si la definición de la key o value cambian, el fichero no se podrá leer.
Para entender de forma visual cómo es la estructura de un SequenceFile, empezamos viendo cómo sería el Header:
 |
| Estructura del Header |
| Estructura de un SequenceFile |
Así sería la estructura de un registro cuando no está comprimido (Uncompressed):
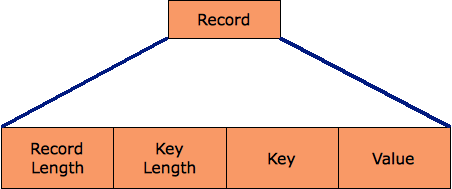 |
| Registro no comprimido |
Y así sería cuando está comprimido por registro (Record Compressed):
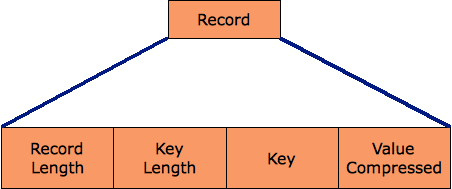 |
| Estructura de la compresión por registro |
Aunque es la misma estructura de SequenceFile, no pueden existir formatos de compresión distintos dentro de un mismo fichero.
A continuación es el formato de un SequenceFile Block Compressed:
| Estructura de un SequenceFile comprimido por bloques |
Y por último el formato del bloque:
 |
| Estructura del bloque comprimido |
Una propiedad de los SequenceFiles es que en la creación introducen puntos de sincronización (sync points).
Estos puntos se pueden utilizar cuando el reader se pierde, por ejemplo, si nos hemos desplazado a buscar en una posición cualquiera en nuestro flujo de datos. Aún más importante, estos puntos de sincronización sirven para definir los InputSplit de los Jobs MapReduce.
Estos sync points se crean automáticamente introduciéndolos cada cierto número de registros cuando realizamos el SequenceFile.Writer.
Se pueden localizar durante la lectura del SequenceFile con el SecuenceFile.Reader a través de:
reader.syncSeen();Otra opción que nos dan los SequenceFiles es, como hemos dicho antes, buscar una posición dada en este tipo de ficheros.
Si sabemos la posición exacta a la que queremos acceder, utilizaríamos el método:
reader.seek(posicion);
reader.next(key, value);Si ponemos una posición que no existe daría un error IOException.
Si no conocemos la posición exacta, podemos utilizar:
reader.sync (posicion)El reader se posicionará en el siguiente sync point que encuentre después de posicion.
Puede ser el caso que el fichero sea muy pequeño y no exista ningún sync point, lo que sucederá entonces es que el reader se posicionará al final del fichero.
Redes sociales