Foro Formación Hadoop
Hoodie: UBER ENGINEERING’S INCREMENTAL PROCESSING FRAMEWORK ON HADOOP
Introducing Hoodie: Hi, Hoodie!
Enter Hoodie, an incremental framework that supports the above requirements outlined in our previous section. In short, Hoodie (Hadoop Upsert Delete and Incremental) is an analytical, scan-optimized data storage abstraction which enables applying mutations to data in HDFS on the order of few minutes and chaining of incremental processing.
Hoodie datasets integrate with the current Hadoop ecosystem (including Apache Hive, Apache Parquet, Presto, and Apache Spark) through a custom InputFormat, making the framework seamless for the end user.
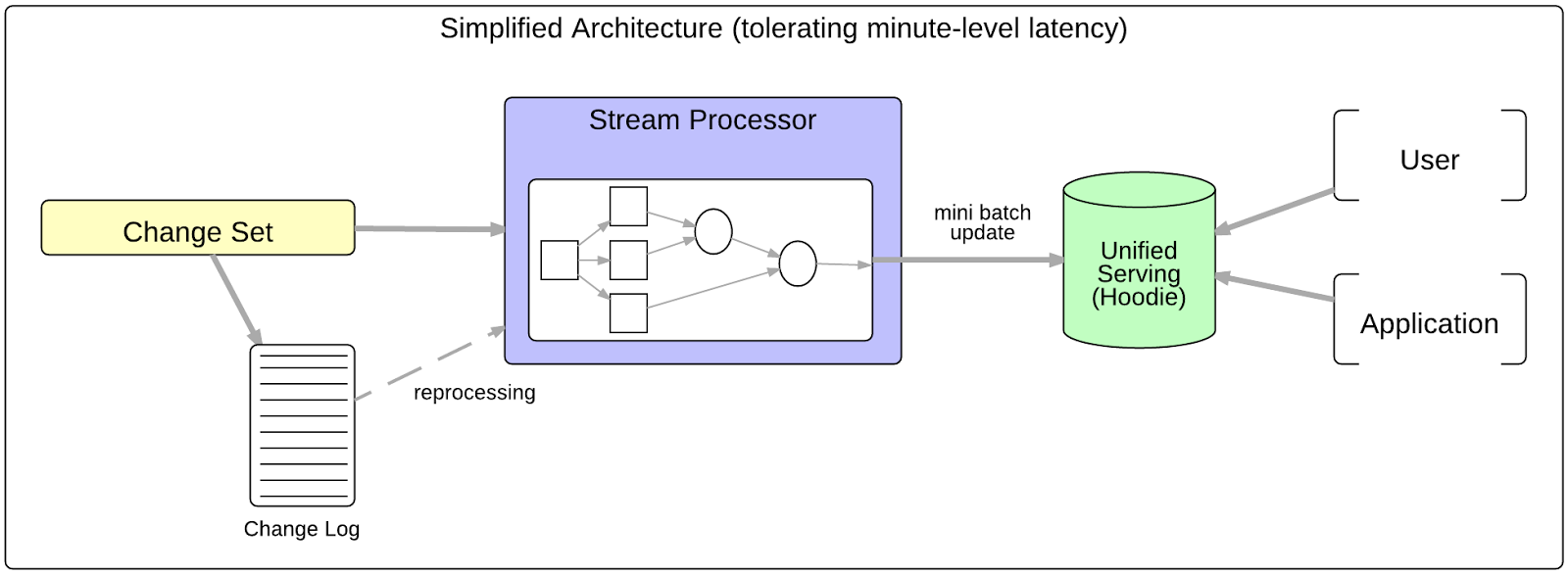
Figure 3: Hoodie simplifies serving for workloads tolerating minute-level latency.
The DataFlow model characterizes data pipelines based on their latency and completeness guarantees. Figure 4, below, demonstrates how pipelines at Uber Engineering are distributed across this spectrum and what styles of processing are typically applied for each:
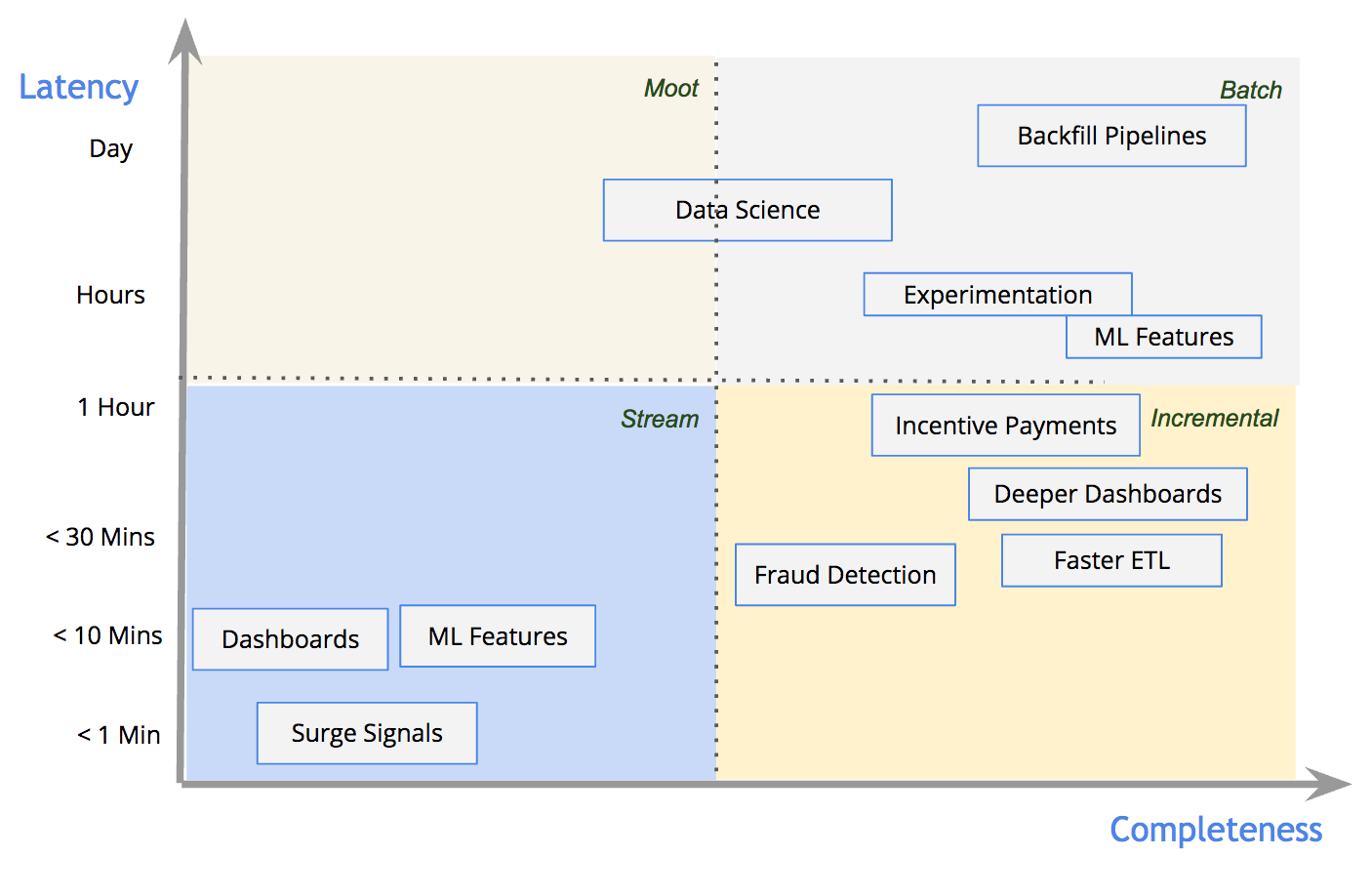
Figure 4: The above diagram demonstrates the distribution of use-cases across different latencies and completeness levels at Uber.
For the few use cases truly needing ~1 minute latencies and dashboards with simple business metrics, we rely on record-level stream processing. For traditional batch use cases like machine learning and experiment effectiveness analysis, we rely on batch processing that excels at heavier computations. For use cases where complex joins or significant data crunching is needed at near real-time latencies, we rely on Hoodie and its incremental processing primitives to obtain the best of both worlds. To learn more about the use cases supported by Hoodie, you can check out our documentation on Github.
Storage
Hoodie organizes a dataset into a partitioned directory structure under a basepath, similar to a traditional Hive table. The dataset is broken up into partitions, which are directories containing data files for that partition. Each partition is uniquely identified by its partitionpath relative to the basepath. Within each partition, records are distributed into multiple data files. Each data file is identified by both an unique fileId and the commit that produced the file. In the case of updates, multiple data files can share the same fileId written at different commits.
Each record is uniquely identified by a record key and mapped to a fileId. This mapping between record key and fileId is permanent once the first version of a record has been written to a file. In short, the fileId identifies a group of files that contain all versions of a group of records.
Hoodie storage consists of three distinct parts:
- Metadata: Hoodie maintains the metadata of all activity performed on the dataset as a timeline, which enables instantaneous views of the dataset. This is stored under a metadata directory in the basepath. Below we’ve outlined the types of actions in the timeline:
- Commits: A single commit captures information about an atomic write of a batch of records into a dataset. Commits are identified by a monotonically increasing timestamp, denoting the start of the write operation.
- Cleans: Background activity that gets rid of older versions of files in the dataset that will no longer be used in a running query.
- Compactions: Background activity to reconcile differential data structures within Hoodie (e.g. moving updates from row-based log files to columnar formats).
- Index: Hoodie maintains an index to quickly map an incoming record key to a fileId if the record key is already present. Index implementation is pluggable and the following are the options currently available:
- Bloom filter stored in each data file footer: The preferred default option, since there is no dependency on any external system. Data and index are always consistent with one another.
- Apache HBase: Efficient lookup for a small batch of keys. This option is likely to shave off a few seconds during index tagging.
- Data: Hoodie stores all ingested data in two different storage formats. The actual formats used are pluggable, but fundamentally require the following characteristics:
- Scan-optimized columnar storage format (ROFormat). Default is Apache Parquet.
- Write-optimized row-based storage format (WOFormat). Default is Apache Avro.
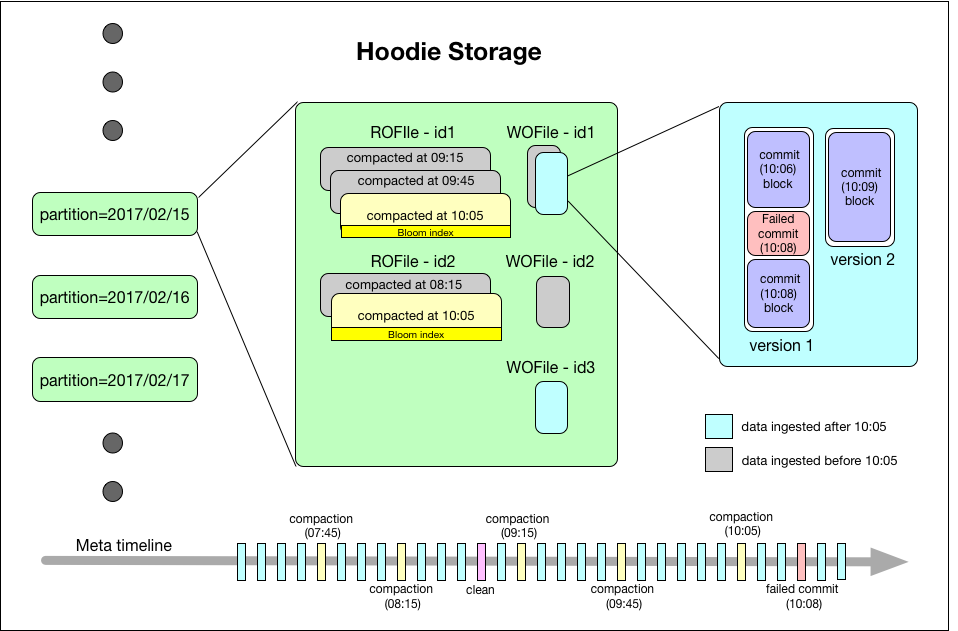
Figure 5: Hoodie Storage Internals. The above Hoodie Storage diagram depicts a commit time in YYYYMMDDHHMISS format and can be simplified as HH:SS.
Información completa (fuente): https://eng.uber.com/hoodie/
Redes sociales