Foro Formación Hadoop
Noticias Big Data
El Big Data creará 4,4 millones de empleos en todo el mundo.... No os quedéis atrás!
http://bigdata.ticbeat.com/big-data-creara-44-millones-empleos-todo-mundo/
Big Data y Hadoop van de la mano
El mercado del almacenamiento y procesamiento de grandes volúmenes de datos está directamente ligado a Hadoop, un framework open-source que pertenece a la fundaciónApache.

Con el fin de facilitar la configuración e instalación de Hadoop, existen diversas distribuciones, tales como Cloudera o Hortonworks entre otras.
Cloudera vs Hortonworks
La distribución de Cloudera (CDH) fue la primera en aparecer en el mercado, combinando Big Data y Hadoop. CDH no solo incluye el núcleo de Hadoop (HDFS, MapReduce…) sino que también integra diversos proyectos de Apache (HBase, Mahout, Pig, Hive, etc.). CDH es 100% open-source, y cuenta con una interfaz gráfica propietaria, Cloudera Manager, para la administración y gestión de los nodos del clúster Hadoop. La descarga es totalmente gratuita. No obstante, también cuenta con una versión empresarial, que incluye una interfaz más sofisticada. Cloudera recientemente ha estrechado vínculos tanto con IBM como conOracle. En la siguiente ilustración, se muestra la arquitectura de la distribución CDH:

- Distribución Cloudera: CDH, vía: http://www.cloudera.com
-
Otra alternativa al Big Data y Hadoop es Hortonworks. A diferencia de Cloudera, Hortonworks es una de las distribuciones más recientes de Hadoop (HDP). Al igual que CDH, HDP es totalmente open-source, incluye las herramientas que forman el núcleo de Hadoop, y por supuesto también incorpora diferentes proyectos open-source de Apache. Para más detalles, la siguiente ilustración muestra la arquitectura de HDP:
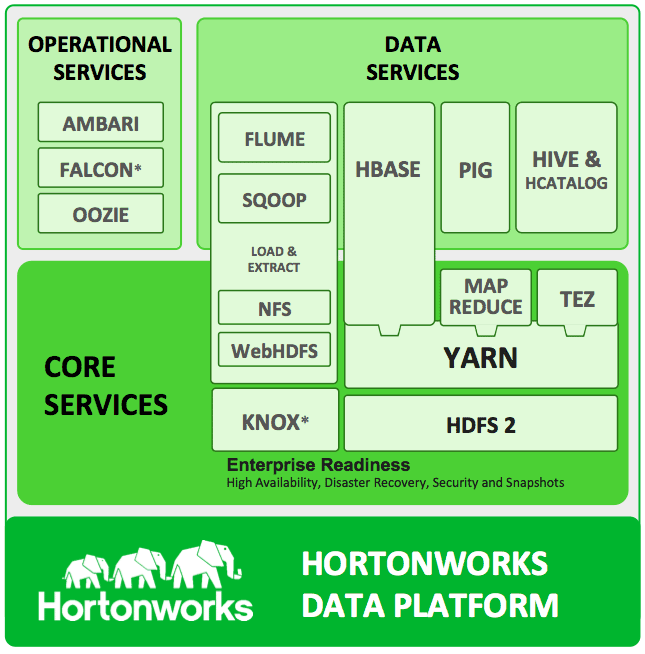
- Distribución Hortonworks: HDP, vía: http://hortonworks.com
Una de las diferencias más notables respecto a Cloudera es la integración de Apache Ambari como herramienta de gestión y administración del clúster. A diferencia del Cloudera Manager, Apache Ambari no es propietario. Sin embargo, el nivel de madurez de la herramienta de gestión de Cloudera es superior a la de Hortonworks. Como partners más cercanos, cuenta con Microsoft e Informatica.
Considerando la importancia de las tecnologías Big Data y Hadoop, el grupo de Telemática de Mondragon Unibertsitatea está inmerso en el desarrollo de dichas tecnologías con el fin de mejorar la eficiencia energética en procesos industriales.

Hadoop tiene ya una intensa historia, y sólo acaba de nacer. No en vano, supo hacer suyo el lema de "divide y vencerás" como ingeniosa y casi milagrosa solución a un problema que parecía irresoluble: gracias a una solución basada en un sistema de archivos distribuidos, consiguió procesar tremendas cantidades de datos que crecían exponencialmente, hasta convertirse en un ecosistema que engloba distintos productos de gran popularidad que hoy se utilizan para almacenar, procesar y analizar datos masivos.
Mucho ha llovido desde sus inicios como diseño a la medida de las necesidades de Google, y ahora son muchos los sectores y situaciones tecnológicas en las que Hadoop puede ser realmente útil para un sinfín de usos, entre otros la inteligencia empresarial (BI), el almacenamiento e integración de datos.
Implementado a partir del código abierto Apache Hadoop o mediante packs que ofrecen muy distintos distribuidores, se trata de un sistema que se puede implementar sobre hardware a un precio comparativamente más bajo que otras plataformas Data Warehouse (DW).
Un menor coste
Al estar basado en un gran número de pequeños ordenadores, cada uno de ellos procesa una parte de la información pero actúan de forma coordinada. De este modo, el resultado es una ventaja comparativa sin competencia: funciona como un ordenador de enormes dimensiones.
Son numerosas sus ventajas con respecto a los sistemas clásicos en almacentamiento y procesamiento de datos pues, al no depender de la cara infraestructura de éstos, permite abaratar costes gracias al uso de servidores estándar, con la posibilidad de ampliarse sin límite.
Dar valor a los grandes datos
El bajo coste, su rápido retorno de la inversión, su robustez, tolerancia a fallos y su ampliación sin límites hace posible una nueva BI basada en el los grandes datos. Con Hadoop, el océano de datos de Big Data es asible. Se abre, pues, una nueva era. Como llegó a decir Leonardo da Vinci, más que una época de cambios, estamos ante un cambio de época pues, sin duda, Big Data y Hadoop representan un gran hito para empresas, organizaciones y sociedad, con un impacto tremendo en todos los órdenes de la sociedad.
Liberar la carga de los DW
Otra ventaja definitiva, su capacidad para adaptarse a los entornos tradicionales de DW, compuestos por datos estructurados y relacionales. ayudando a obtener valor de BI supliendo esta carencia. A esto hay que añadir la posibilidad de "descargar el mayor número posible de tareas en HDFS y otras tecnologías Hadoop, pues son menos caras, con el resultado de liberar los recursos de DW para cargas de trabajo en las que pueden ofrecen un rendimiento superior", apunta Philip Russorn, director de investigación de Gestión de Datos en The Data Warehousing Institute (TDWI).
Russorn también subraya la importancia de los usos menos conocidos para Hadoop, entre otros la gestión de "datos que proceden de dispositivos de detección, las aplicaciones de análisis avanzado más antiguas que necesitan grandes muestras de datos, ya sea la segmentación de las bases de clientes, la detección del fraude o el análisis del riesgo", concluye.

Mucho se habla este año de alternativas a Hadoop para manejar datos masivos. Sin duda la que más espectación está levantando es el proyecto Apache Spark, cuyos seguidores crecen como la espuma. ¿Desplazará Spark al otrora omnipresente Hadoop?
Vamos a hacer una revisión, tomando información entre otras* del sitio oficial de Apache Spark. Recomiendo encarecidamente revisar los enlaces que incluyo abajo si queréis ahondar en aspectos técnicos, pues se han hecho algunos estudios muy completos ya acerca de Spark.
Originalmente desarrollado como un proyecto de investigación en AMPLab de la UC Berkeley, el proyecto ha alcanzado el estatus de la incubadora de Apache en junio de 2013. Se trata de un framework de computación distribuida open source.
Databricks, la empresa fundada para apoyar Spark recaudó recientemente $ 14M del VC Andreessen Horowitz. A su vez Cloudera ha decidido apoyar plenamente Spark. Para muchos esta plataforma híbrida es la próxima Big Thing.
Cuál es la mejora?
- Rapidez: Spark es capaz de ejecutar los trabajos por lotes de procesamiento de entre 10 a 100 veces más rápido que el motor MapReduce acuerdo con Cloudera, principalmente mediante la reducción del número de escrituras y lecturas de disco.
- Real time batch procesing: En lugar de simplemente procesar un lote de datos almacenados, como es el caso de MapReduce, Spark también puede manipular los datos en tiempo real utilizando Spark Streaming.
Esta capacidad permite que las aplicaciones pasen datos a través de una función de software – por ejemplo, para llevar a cabo análisis al mismo tiempo que los datos son recogidos. - Alta tolerancia a fallos: En lugar de la persistencia o la existencia de checkpoints en resultados intermedios, Spark recuerda la secuencia de operaciones que llevó a un determinado conjunto de datos. Así que cuando falla un nodo, Spark reconstruye el conjunto de datos basado en la información almacenada. Esto proporciona una cierta estabilidad que permite que no se caida todo un proceso cuando aparecen fallos en alguno de los nodos.
- Facilidad de uso: La implementación tanto de stream como de batch processing en la parte superior de Spark podría eliminar gran parte de la complejidad que las organizaciones se están encontrando en las abstracciones de MapReduce, y permitirá simplificar el despliegue, mantenimiento y desarrollo de aplicaciones.
- Conectividad, multiplataforma: Un conjunto de APIs para el motor de ejecución de Spark están disponibles en Java, Python y Scala, lo que permite a los desarrolladores escribir aplicaciones que se pueden ejecutar en la parte superior de Spark en estos idiomas. Spark puede interactuar con los datos en el HDFS (Sistema de archivos de Hadoop), la base de datos HBase Hadoop, el almacén de datos Cassandra y varias otras capas de almacenamiento.
In-Memory: la próxima revolución del Big Data nos viene a la memoria
Spark está diseñado para ejecutarse por defecto en memoria, por lo que los desarrolladores pueden escribir algoritmos iterativos sin escribir un conjunto de resultados después de cada pasada. Esto permite un alto rendimiento en la analítica avanzada, mediante técnicas como la regresión logística.


Es un sistema 100% compatible con Hadoop2.0 y su interconexión es a través de YARN
Los datos con ruido y otros desafíos a los que se enfrenta Big Data
Aunque subirse al carro del análisis de las grandes cantidades de datos que generan las empresas actuales parece una tarea irrenunciable, se trata de un fenómeno con retos por resolver.
Cada vez se generan más datos y cada vez se maneja más información procedente de fuentes de lo más diverso, por lo que profundizar en las técnicas de análisis de dicho material se vuelve una tarea fundamental. El Big Data ha llegado para quedarse y para marcar la diferencia en empresas de todos los sectores, guiándolas a la hora de tomar decisiones y fortaleciéndolas frente a la competencia.
![]() Pero eso no quiere decir que avanzar en temas de Big Data sea pan comido. Este fenómeno se enfrenta a cinco retos fundamentales, según la firma Teradata:
Pero eso no quiere decir que avanzar en temas de Big Data sea pan comido. Este fenómeno se enfrenta a cinco retos fundamentales, según la firma Teradata:
1. “El reto de los datos multi-estructurados”. Como decíamos, los datos que se crean y almacenan en masa cada día tienen una naturaleza muy diversa. No sería lo mismo tratar con la información procedente de Data Warehouse que con las fuentes más modernas de información. “Social data and machine log data se caracterizan por su volatilidad”, advierten desde Teradata, por lo que “el modelo de información que usamos para entenderlos puede ser implícito en lugar de explícito”, “incluir algún nivel de organización jerárquica” o quizás no y, aparte, “cambiar continuamente”.
2. “El desafío de las analíticas interactivas”. Del mismo modo, realizar monitorizaciones de datos en tiempo real e intentar dar sentido lo antes posible a aquellas relaciones que se producen entre unos y otros, para aprovechar su potencial en beneficio de la empresa, es un desafío notable. El hecho de que la tecnología ANSI SQL, además, no ensalce el orden de registro supondría un problema. Los expertos consideran que características como UDF y OLAP representan únicamente “una solución parcial”.
3. “El reto de los datos con ruido”. La falta de rigurosidad también amenazaría al Big Data. No todos los datos son igual de fáciles de interpretar y los analistas no recurrirían a todos ellos con la misma frecuencia para realizar su trabajo. Teradata da a entender que “algunos grupos de Big Data” son empleados con la intención última de “ayudar al procesamiento asociado con objetivos de nivel de servicio relajados y sin valor probado”.
4. “El reto de ‘puede haber una aguja en un pajar pero si se necesitan doce meses y 500.000 € para averiguarlo no hay tiempo ni dinero para investigarlo'”. O, dicho de otro modo, el Big Data puede perder eficacia si su estudio y el establecimiento consecuente de conclusiones se prolonga demasiado en el tiempo o si ni siquiera se tiene muy claro por dónde empezar el análisis. Además, no es una tarea barata ni que se pueda acometer reutilizando un enfoque de Data Integration tradicional. Por ejemplo, la compra, estandarización “e integración de datos representan hasta el 70% del coste total de implementar una base de datos analítica”, dicen quienes saben de esto.
5. “El reto de ir más allá y el valor de la entrega”. No se puede abrazar el fenómeno Big Data sin un motivo o, simplemente, porque los competidores también lo estén haciendo. Hay que ser más incisivos. Hay que intentar exprimir al máximo las posibilidades de esta tendencia de negocio y situarse incluso un paso más delante de la mejora global de los conocimientos que se tienen, transformando “el negocio y así impulsar el retorno de la inversión”. Teradata también señala que, por sí solo, un Data Scientist no es garantía de nada.
En savoir plus sur http://www.siliconweek.es/noticias/los-datos-con-ruido-y-otros-desafios-los-que-se-enfrenta-big-data-68373#XU6DRxiEIitM28bP.99
How To Get Started with Cascading and Hadoop on Hortonworks Data Platform
The power of a well-crafted speech is indisputable, for words matter—they inspire to act. And so is the power of a well-designed Software Development Kit (SDK), for high-level abstractions and logical constructs in a programming language matter—they simplify to write code.
In 2007, when Chris Wensel, the author of Cascading Java API, was evaluating Hadoop, he had a couple of prescient insights. First, he observed that finding Java developers to write Enterprise Big Data applications in MapReduce will be difficult and convincing developers to write directly to the MapReduce API was a potential blocker. Second, MapReduce is based on functional programing elements.
With these two insights, Wensel designed the Java Cascading Framework, with the sole purpose of enabling developers to write Enterprise big data applications without the know-how of the underlying Hadoop complexity and without coding directly to the MapReduce API. Instead, he implemented high-level logical constructs, such as Taps, Pipes, Sources, Sinks, and Flows, as Java classes to design, develop, and deploy large-scale big data-driven pipelines.
Sources, Sinks, Traps, Flows, and Pipes == Big Data Application
At the core of most data-driven applications is a data pipeline through which data flows, originating from Taps and Sources (ingestion) and ending in a Sink (retention) while undergoing transformation along a pipeline (Pipes, Traps, and Flows). And should something fail, a Trap (exception) must handle it. In the big data parlance, these are aspects of ETL operations.
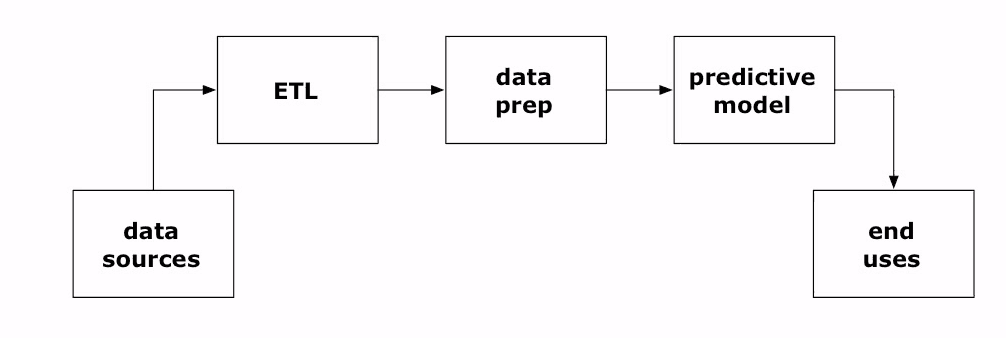
The Cascading SDK embodies these plumbing metaphors and provides equivalent high-level Java constructs and classes to implement your sources, sinks, traps, flows, and pipes. These constructs enable a Java developer eschew writing MapReduce jobs directly and design his or her data flow easily as a data-driven journey: flowing from a source and tap, traversing data preparation and traps, undergoing transformation, and, finally, ending up into a sink for user consumption.
Now, I would be remiss without showing the WordCount example, the equivalent of the Hadoop Hello World, to illustrate how these constructs translate into MapReduce jobs, without understanding the underlying complexity of the Hadoop ecosystem. That simplicity is an immediate and immense draw for a Java developer to write data-driven Enterprise applications at scale on top of the underlying Hortonworks Data Platform (HDP 2.1). And the beauty of this simplicity is that your entire data-driven application can be compiled as a jar file, a single unit of execution, and deployed onto the Hadoop cluster.
So let’s explore the wordcount example, which can be visualized as a pattern of data flowing through a pipeline under going transformation, beginning from a source (Document Collection) and ending into a sink (Word Count).

In a single file, Main.java, I can code my data pipeline into a MapReduce program using Cascade’s high-level constructs and Java classes. For example, below is a complete source listing for the above transformation.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
package impatient; import java.util.Properties; import cascading.flow.Flow; import cascading.flow.FlowDef; import cascading.flow.hadoop.HadoopFlowConnector; import cascading.operation.aggregator.Count; import cascading.operation.regex.RegexFilter; import cascading.operation.regex.RegexSplitGenerator; import cascading.pipe.Each; import cascading.pipe.Every; import cascading.pipe.GroupBy; import cascading.pipe.Pipe; import cascading.property.AppProps; import cascading.scheme.Scheme; import cascading.scheme.hadoop.TextDelimited; import cascading.tap.Tap; import cascading.tap.hadoop.Hfs; import cascading.tuple.Fields; public class Main { public static void main( String[] args ) { String docPath = args[ 0 ]; String wcPath = args[ 1 ]; Properties properties = new Properties(); AppProps.setApplicationJarClass( properties, Main.class ); HadoopFlowConnector flowConnector = new HadoopFlowConnector( properties ); // create source and sink taps Tap docTap = new Hfs( new TextDelimited( true, "\t" ), docPath ); Tap wcTap = new Hfs( new TextDelimited( true, "\t" ), wcPath ); // specify a regex operation to split the "document" text lines into a token stream Fields token = new Fields( "token" ); Fields text = new Fields( "text" ); RegexSplitGenerator splitter = new RegexSplitGenerator( token, "[ \\[\\]\\(\\),.]" ); // only returns "token" Pipe docPipe = new Each( "token", text, splitter, Fields.RESULTS ); // determine the word counts Pipe wcPipe = new Pipe( "wc", docPipe ); wcPipe = new GroupBy( wcPipe, token ); wcPipe = new Every( wcPipe, Fields.ALL, new Count(), Fields.ALL ); // connect the taps, pipes, etc., into a flow FlowDef flowDef = FlowDef.flowDef() .setName( "wc" ) .addSource( docPipe, docTap ) .addTailSink( wcPipe, wcTap ); // write a DOT file and run the flow Flow wcFlow = flowConnector.connect( flowDef ); wcFlow.writeDOT( "dot/wc.dot" ); wcFlow.complete(); } } |
First, we create a Source (docTap) and a Sink (wcTap) with two constructors, new Hfs(…). The RegexSplitGenerator() class defines the semantics for a Tokenizer (see diagram above).
Second, we create two Pipe(s), one for the tokens and the other for word count. To the word count Pipe, we attach aggregate semantics how we want our tokens to be grouped by using a Java construct GroupBy.
Once we have two Pipes, we connect them into a Flow by defining a FlowDef and using the HadoopFlowConnector.
And finally, we connect the pipes and run the flow. The result of this execution is a MapReduce job that runs on HDP. (The dot file is a by-product and maps the flow; it’s a good debugging tool to visualize the flow.)
Note that nowhere in the code is there any reference to mappers and reducers’ interface. Nor is there any indication of how the underlying code is translated into mappers and reducers and submitted to Tez or YARN.
As UNIX Bourne shell commands are building blocks to a script developer, so are the Cascading Java classes for a Java developer—they provide higher-level functional blocks to build an application; they hide the underlying complexity.
For example, a command strung together as “cat document.tweets | wc -w | tee -a wordcount.out” is essentially a data flow, similar to the one above. A developer understands the high-level utility of the commands, but is shielded from how the underlying UNIX operating system translates the commands into a series of forks(), execs(), joins(), and dups() and how it joins relative stdin and stdout of one program to another.
In a similar way, the Cascading Java building blocks are translated into MapReduce programs and submitted to the underlying big data operating system, YARN, to handle any parallelism and resource management on the cluster. Why force the developer to code directly to MapReduce Java interface when you can abstract it with building blocks, when you can simplify to write code easily?
What Now?
The output of this program run is shown below. Note how the MapReduce jobs are submitted as a client to YARN.
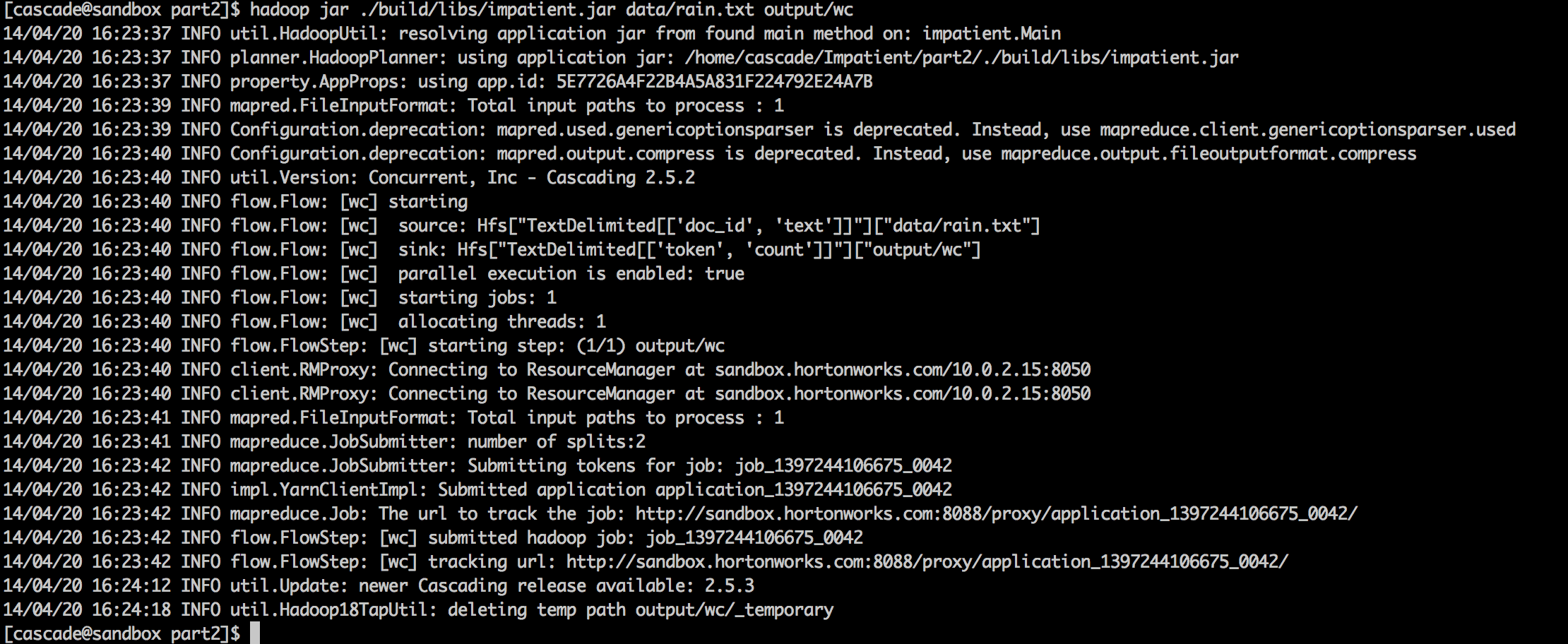
Even though the example presented above is simple, the propositions from which the Cascading SDK was designed—high-level Java abstractions to shield the underlying complexity, functional programming nature of MapReduce programs, and inherent data flows in data-driven big data applications—demonstrate the simplicity and the ability to easily develop data-driven applications and deploy them at scale on HDP while taking advantage of underlying Tez and YARN.
As John Maeda said, “Simplicity is about living life with more enjoyment and less pain,” so why not embrace programming frameworks that deliver that promise—more enjoyment, easy coding, increase in productivity, and less pain.
What’s Next?
Associated with The Cascading SDK are other projects such as Lingual, Scalding, Cascalog, and Pattern. Together, they provide a comprehensive data application framework to design and develop Enterprise data-driven applications at scale on top of HDP 2.1.
To dabble your feet and whet your appetite, you can peruse Cascading’s tutorials on each of these projects.
For hands-on experience on HDP 2.1 Sandbox for the above example, which is derived from part 2 of the Cascading’s Impatient series, you can follow this tutorial.
http://hortonworks.com/blog/cascading-hadoop-big-data-whatever/
New in CDH 5.3: Transparent Encryption in HDFS
http://blog.cloudera.com/blog/2015/01/new-in-cdh-5-3-transparent-encryption-in-hdfs/
El big data ha movido 441 millones de euros en España durante 2014
La investigación de mercados o el big data ha movido en España 441 millones de euros el año pasado. Esta es la cifra neta registrada en el ‘Estudio sobre la Investigación de Mercados 2014’, elaborado por AEDEMO (Asociación Española de Estudios de Mercado, Marketing y Opinión), Aneimo (Asociación de Empresas de Investigación de Mercados y Opinión) y Esomar (Sociedad Europea de Opinión e Investigación de Mercados).
Esta cifra neta de negocio, señala el informe, es un ‘tímido crecimiento del 0,7%’ pero que ‘sabe a éxito después de unos años marcados por la recesión’. El sector de la investigación es cada vez más digital y cada vez la tecnología ocupa un papel más protagonista. Los datos indican que la recogida de datos por medios electrónicos, automáticos y online supone ya la mitad del total mercado (49,9%). En consecuencia, disminuyen el resto de métodos (postal, telefónico, presencial).
http://prnoticias.com/marketing/20142319-big-data-millones-espana
Jordi Griful: "El Big Data generará miles de puestos de trabajo"
Tener más datos permite tomar mejores decisiones, y el reto de tomar medidas en tiempo real

Jordi Griful, CEO de Quantion
- Enviar por correo
- Cuerpo de letra
- Imprimir noticia
Xantal Llavinia
Miércoles, 3 de febrero del 2016 - 10:58 CET
En Europa hay un mercado Big Data valorado en 50.000 millones de euros y en más de 6 millones de trabajadores. En el mundo, el Big Data generará 900.000 puestos de trabajo en seis años y se calcula que las empresas que hacen un uso inteligente de los datos incrementan un 8 por ciento su productividad. Nos lo cuenta Jordi Griful, alma de la empresa tecnológica Quantion y miembro del Círculo de Economía.
“Gestionar grandes volúmenes de datos, a la mayor velocidad posible, desde una gran variedad de fuentes distintas”
Para el que aún no lo tenga del todo claro, ¿qué es el Big Data y en qué beneficia?
El hecho de tener más datos nos permite tomar mejores decisiones y el reto de tomar medidas en tiempo real. El Big Data es una gran oportunidad para el Business Intelligence porque supone sacar más y mejores conocimientos.Trabajamos con grandes volúmenes de información pero actualmente se ha generalizado el término “Big Data” para afrontar la labor de: almacenar, organizar, analizar y distribuir las grandes cantidades de información. Se trata de gestionar correctamente las denominadas “tres uves”: gestionar grandes Volúmenes de datos, a la mayor Velocidad posible, desde una gran Variedad de fuentes distintas.
Lo leemos en todos los sitios, el Big Data es el futuro, ¿de dónde surgirán tantos puestos de trabajo?
Con la llegada de la Transformación Digital vemos que por un lado muchos puestos de trabajo van a ser automatizados, y por tanto con el tiempo substituidos, mientras que por el otro existen infinidad de tecnologías nuevas y capacidades de proceso que no existían antes. Por eso, hoy las empresas tienen una necesidad imperiosa de aprovechar al máximo los datos que generan tanto ellas mismas y sus clientes, como el mercado para tomar mejores decisiones para sus negocios.
El Big Data genera diferentes perfiles con nuevos roles ( CDO Chief Digital Officer, Analista Digital y Data Scientist ). El abanico es muy amplio: matemáticos, humanistas, investigadores…hasta los más técnicos y tecnológicos.
Datos, datos, datos…. Sensores en semáforos para contabilizar el número de personas o de vehículos que transitan en un punto para mejorar la circulación; cámaras inteligentes vinculadas a la posición GPS de un usuario para que una persona reciba ofertas al pasar por una tienda… ¿qué ejemplo será el más revolucionario?
Según las tendencias tecnológicas, la Inteligencia Artifical (IA) será la tecnología predominante en lo que se refiere al análisis de datos y Big Data en 2016.
“Monitorizar en tiempo real el efecto de medicamentos sobre enfermedades”
Póngame, tres aplicaciones con éxito que utilizan el Big Data….
Por ejemplo, en Seguros: calcular con éxito la cuota del seguro que deben pagar los usuarios en función de los datos obtenidos según la forma de conducir. En Farmacias, monitorizar en tiempo real el efecto de medicamentos sobre enfermedades y evaluar su grado de efectividad. En Banca, conocer el riesgo de los mercados en tiempo real en función de los datos obtenidos de las transacciones y cotizaciones. Conocer mejor a los clientes para ofrecer un trato personalizado...
Más ejemplos…
En el transporte, conseguir la optimización de rutas en tiempo real a partir de datos de tráfico, meteorológicos y paradas obligatorias de ruta. Y en el caso de la educación, últimamente aparecen cada vez más aplicaciones que aprenden de las acciones de los usuarios con ejercicios de formación y que son capaces de proponernos el siguiente ejercicio a realizar para maximizar el desarrollo cognitivo del usuario.
El Centro de Excelencia en Big Data de Barcelona y, vosotros, Quantion ayudáis a las empresas a optimizar la gestión de datos masivos. Póngame otro caso real…
Imagínate, por ejemplo, los pisos turísticos y su problemática actual en cuanto a detección de la oferta y demanda, su gestión en cuanto a cumplimiento (permisos, licencias) o no cumplimiento (fraude fiscal, inseguridad ciudadana). Todo son datos que se pueden obtener de diversas fuentes, tramitar, agregar información de valor y por tanto tomar decisiones al respecto.
Y suena también mucho el Data Analytics, ¿en qué se diferencia del Big Data?
Mientras el Big Data se encarga de analizar, interpretar y capturar el valor de los datos. El Data Analytics consiste en aprovechar los datos recogidos para realizar análisis predictivos y de tendencias.
“La tecnología puede impactar para mejoras sociales, beneficios culturales, de formación y educación”
En el caso de una administración pública, ¿cómo sería una buena gestión inteligente de datos en Internet?
De la misma forma que hace años se construyeron autopistas ahora, y salvando las distancias, estamos en circunstancias parecidas pero con la información. Dicho esto y siguiendo mi ejemplo, lo primero que haría sería evitar hipotecas o sea peajes… Después tendría en cuenta que quien más está digitalizado es el propio ciudadano. Para avanzar en la inteligencia de datos en las ciudades se requiere integrar, conectar y aprovechar interdependencias, dentro y fuera de la administración pública. Muchos hablan de Smart cities y creo que una buena orientación seria ver y evaluar como la tecnología puede impactar para mejoras sociales, beneficios culturales, de formación y educación. Creo que antes de nada, se necesita entender bien el impacto de la digitalización en la gobernanza para poder desplegar en la administración infraestructuras TIC esenciales.
Y mientras, ¿nuestra privacidad está protegida en estos tiempos de información masiva?
No solo las empresas, sino también los gobiernos, deben llevar a cabo iniciativas que se adapten a la realidad empresarial y al escenario actual de fraude y amenazas en Internet como el robo de tarjetas de crédito, el robo de credenciales, las fugas de información y las nuevas generaciones de malware. Lo que no se puede hacer es ignorar el grado de avance y potencialidad de las nuevas tecnologías. Tal vez implicará nueva legislación y probablemente incluso nuevas fórmulas para gestión de situaciones conflictivas al respecto.
¿La base de datos más grande actualmente, la tiene Google?
La base de datos y mucho más... Google ha creado una multiempresa, multidisciplinar y multiservicio. Cuando alguien te dice que solo es un buscador de internet puedes empezar a temblar…
¿Los datos masivos han logrado que Facebook o Amazon sean muy buenos negocios?
Es obvio que hasta ahora sí. En la transformación digital un reto clave es, por ejemplo, la personalización, conocer quien es tu cliente siempre tanto a nivel on line como off line. Cuando estas en internet y cuando estas presencial y físicamente en mis instalaciones.
Por otro lado el reto es ver como se mantienen y en todo caso como evolucionan. Solo tienes que ver otros casos como por ejemplo Twitter. El avance de las nuevas tecnologías es imparable y está bien prescrito por todos los analistas...
Fuente y noticia completa: http://www.elperiodico.com/es/noticias/entrevistas-talento-digital/entrevista-jordi-griful-big-data-generara-miles-puestos-trabajo-4867709#
Social networks