Foro Formación Hadoop
Ejercicio. Ejecutando un Workflow con Hue.
Buenas Tardes,
Estoy con el último ejercicio del módulo 1. En el se pide ejecutar un workflow con Hue y me esta dando problemas:
No consigo añadir el jar ni añadir las propertis, dónde se añaden las propertis??.
Gracias.
Hola Andrés,
Entendemos que estás utilizando la VM de Cloudera para realizar los ejercicios. Para poder ayudarte necesitamos que nos digas que versión estás utilizando.
Un saludo,
Estoy utilizando Cloudera Manager la versión 5.12.
Gracias.
Hola Andrés,
La interfaz de la última versión de HUE en la distribución de Cloudera ha cambiado bastante. Debe acceder a query/scheduler/workflow.
Una vez en el editor de workflow podrá generar su workflow seleccionando la acción de MapReduce. El jar de MapReduce que desea ejecutar debe estar en el HDFS.
A continuación le indicamos unas capturas para intentar ayudarle:
Acceso al editor de oozie:
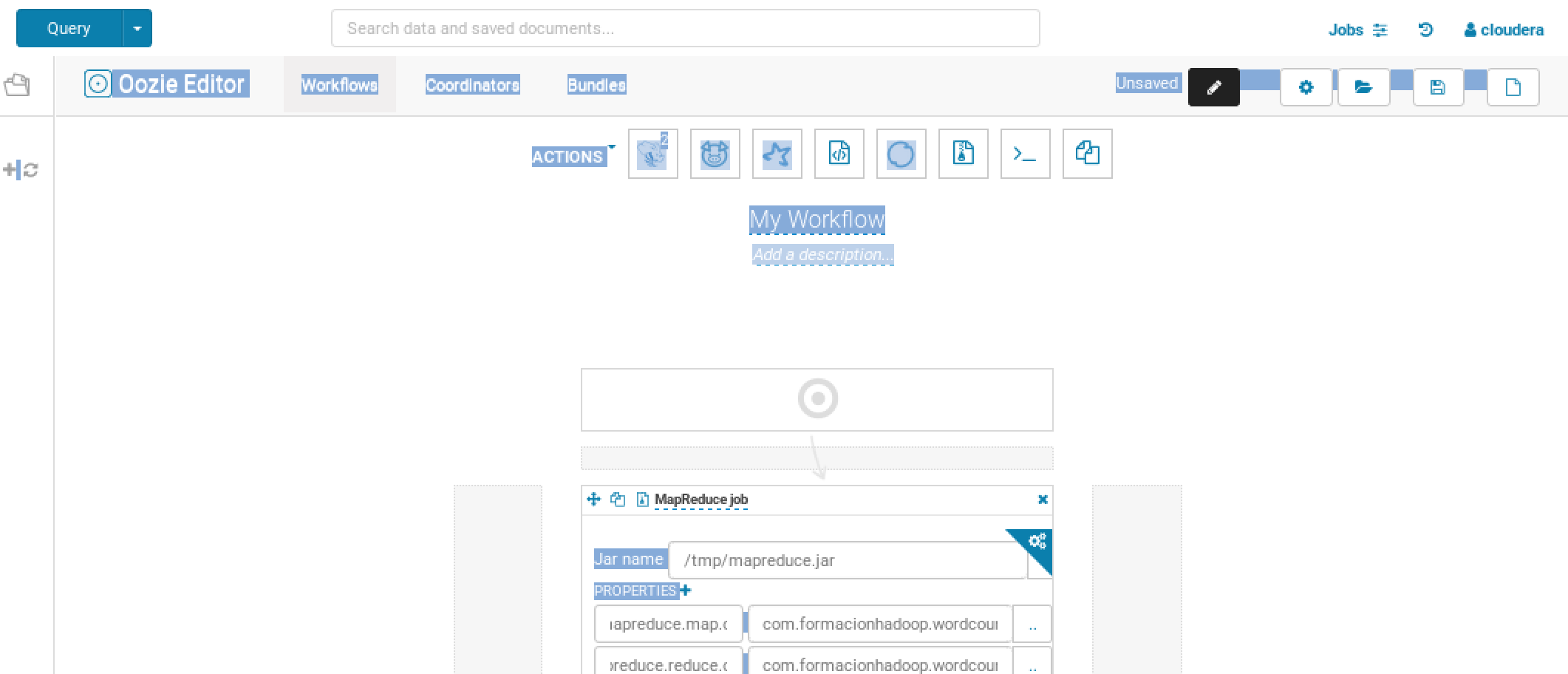
Panel/editor de creación de workflows:
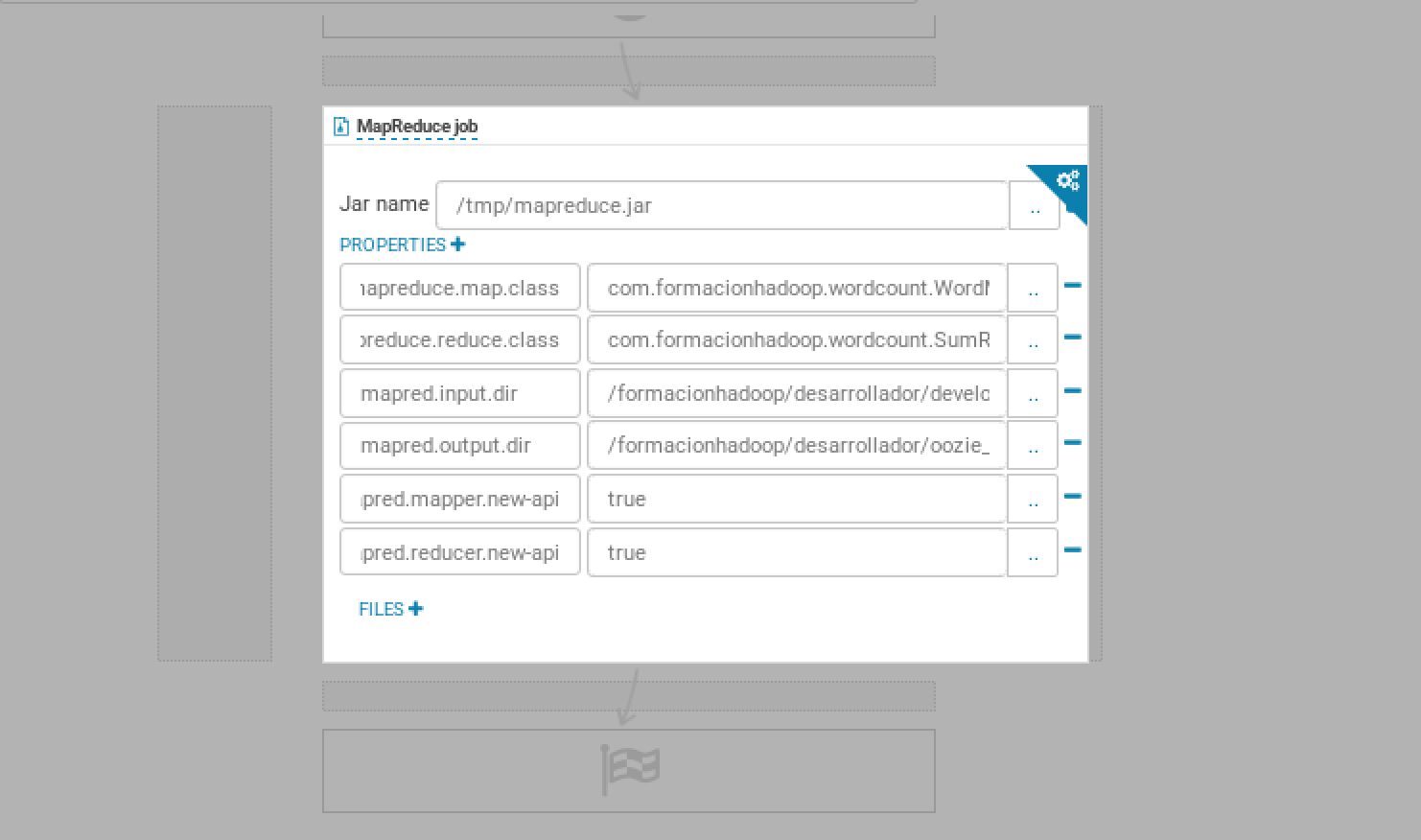
Ejemplo configuración acción MapReduce:
Un saludo,
Hasta ahí he llegado yo, no me soluciona nada.
Yo arrastro Save MapReduce Job al recuadro dónde pone: Drop your action here.
Cuándo hago eso me sale una pantalla para introducir mi programa MapReduce, introduzco el wordcount-1.jar como pone en los apuntes pero no me deja añadirlo....
¿El wordcount-1.jar lo tienes en HDFS?
Pues entiendo que si, ya que he seguido los pasos de los ejercicios. Aún así como se miraba en la terminal si esta en el HDFS??????
Al inicio del ejercicio se indica:
-
Si no lo hiciste, debes crear el JAR siguiendo los pasos del ejercicio WordCount. Nota: el Reducer de este ejercicio realiza la misma función que el del programa WordCount que ejecutaste antes. Puedes reutilizar ese código o puedes escribir uno nuevo.
Para comprobar que el jar está en HDFS debes utilizar el comando visto en capítulos anteriores (hadoop fs -ls) indicando la ruta donde has dejado el jar, por ejemplo, si el jar lo pusiste en /tmp del hdfs:
hadoop fs -ls /tmp
Al ejecutar el comando anterior deberías ver el .jar generado.
En el hue debes insertar la ruta completa (por ejemplo: /tmp/wordcount.jar)
Yo tengo mi wordcount-1.jar en el escritorio y en cloudera`s home en la carperta Temp.
Por tanto en la terminal entro en el escritorio (cd Desktop), una vez ahí busco hadoop fs -ls /wordcount-1.jar y nada.
Está claro que hago algo mal pero no se el que...
Tienes varios conceptos "difusos". Por una parte tenemos el sistema de ficheros local (el escritorio, home, etc.. que tendríamos en cada una de las máquinas que forman nuestro cluster Hadoop), y por otra parte tenemos el sistema de ficheros de Hadoop (HDFS) que lo componen todas las máquinas del cluster.
Para moverte por el sistema de ficheros local, utilizas los comandos de unix, cd ..., ls .. etc.
Para realizar acciones sobre el sistema de ficheros de Hadoop se realizan a través del cliente "hadoop fs".
Con todo esto, si tienes el wordcount-1.jar en el escritorio (sistema de ficheros local) para insertarlo en el tmp de HDFS debes realizar:
cd Desktop
hadoop fs -put wordcount-1.jar /tmp
A continuación, si haces un listado del tmp de HDFS verás el jar:
hadoop fs -ls /tmp
Recordarte que si en la terminal indicas únicamente la instrucción hadoop fs, te muestra un listado con todas las operaciones disponibles.
Si no te aclaras con estas cosas, te recomendaríamos que revisar los 2 primeros ejercicios del módulo 1.
Un saludo.
Hago lo que me indicas en el post de arriba:
- cd Desktop
- hadoop fs -put wordcount-1.jar /Temp
Me sale lo siguiente:
- put: Permission denied: user=cloudera, access=write, inode="/":hdfs:supergroup:drwxr-xr-x
Tengo el cloudera manager con la sesión abierta y nada.
Hola Andrés,
Estás poniendo mal la instrucción de hadoop fs -put:
Tu estás poniendo:
hadoop fs -put wordcount-1.jar /Temp
Y en el post de arriba se indica:
hadoop fs -put wordcount-1.jar /tmp
Un saludo,
Buenas, siento ser tan pesado....
Ejecuto: hadoop fs -ls /tmp
Me sale:
Found 6 items
drwxrwxrwx - hdfs supergroup 0 2017-11-14 07:13 /tmp/.cloudera_health_monitoring_canary_files
drwxrwxrwt - mapred mapred 0 2017-07-19 05:34 /tmp/hadoop-yarn
drwx--x--x - hbase supergroup 0 2017-10-09 01:06 /tmphbase-staging
drwx-wx-wx - hive supergroup 0 2017-11-02 08:17 /tmp/hive
drwxrwxrwt - mapred hadoop 0 2017-10-09 23:40 /tmp/logs
-rw-r--r-- 1 cloudera supergroup 3367 2017-11-14 05:16 /tmp/wordcount-1.jar
Añado el MapReduce en HUE.
Introduzco el jar: /tmp/wordcount-1.jar le doy a ADD y no me lo añade....
Que me puede estar pasando??? Gracias!!
Social networks